UTF-7,编码解码工具,可直接用于跨站脚本攻击xss
”UTF-7 编码工具 解码工具 UTF7编码“ 的搜索结果

手动实现UTF-8编码
谈谈 UTF-8 标准和解码的实现
标签: c++
unicode + utf-8 + Cpp implement
UTF7 编码及解码工具 用于XSS方面
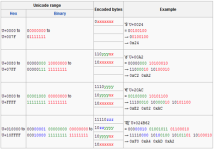
Utf-8编码与解码(vb6代码) 用VB做爬虫时遇到的乱码问题,编解码方式不对造成,用这个方法使各种编码方式之间互相转化
System.out.println("“我是林纳斯”这句话的的按utf-8解码的字节数组为:"+Arrays.toString(a.getBytes(StandardCharsets.UTF_8))); System.out.println("字节数组按utf-8编码为: "+new String(ne
简单介绍一下utf-8编码,utf-8编码是一种变长的编码方式,长度为1-4字节。 当码长为1字节的时候,兼容ascii编码,格式为0xxxxxxx (x处表示有效位) 当码长为2字节的时候,格式为110xxxxx 10xxxxxx 高字节的110...
utf-8编码规则计算出一个数字二进制,然后根据它的二进制长度把它们塞到一个特殊序列的二进制中: 1字节 0xxxxxxx (0-127) 2字节 110xxxxx 10xxxxxx (128-2047) 3字节 1110xxxx 10xxxxxx 10xxxxxx (2048-65535) ...
目 录 1 编码 1 2 编码代码(C++) 2 ... UTF-7编码的规则及特点为: 1)UTF16小于等于 0x7F 的字符,采用ASCII编码; 2)UTF16大于0x7F的字符,采用Base64编码,然后在首尾分别加上+


JavaScript本身可通过charCodeAt方法得到一个字符的Unicode编码,并通过fromCharCode方法将Unicode编码转换成对应字符。...不过有一个简便的办法来实现UTF-8的编码与解码。Web要求URL的查询字符串采用UTF...
JavaScript本身可通过charCodeAt方法得到一个字符的Unicode编码,并通过fromCharCode方法将Unicode编码转换成对应字符。...不过有一个简便的办法来实现UTF-8的编码与解码。 Web要求URL的查询字符串采...
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理...
UTF-8编码的原理
标签: 学习

该文件是用于Unicode字符的UTF-8编码文件。 我想打印前10个UTF-8字符,但是下面代码片段的输出显示了10个无法识别的怪异字符。 想知道是否有人对如何正确打印有任何想法? 谢谢。with open(name, 'r') as content_...
在计算机世界中,只有0、1两种数字,不论是英文、中文还是数字,在计算机中都是以01的形式存储的。因此,要想把文字存储到计算机上...编码就是规定特定的01序列来表示文字的过程,编码表示了字符在计算机中的存储形式。

1、ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。...
内容仅用于个人学习,如有侵权请联系删除~ ... 编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程) 广义的 Unicode 是一个标准,定义了一个字符集以及一系列的编码规则,即 Unic.
1.url编码 ios中http请求遇到汉字的时候,需要转化成UTF-8,用到的方法是: NSString * encodingString = [urlString stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding]; 2.url解码 ...

UTF-8的编码规则
标签: 嵌入式
UTF-8的编码规则: 1、对于单字节的字符,字节的第一位设为0,后面七位为这个字符的Unicode码。 因此对于英文字符,UTF-8编码和ASCII码是相同的。 2、对于n字节的字符(n>1),第一个字节的前n位都设为1,第n+1位设...
中文转UTF-8 (中文).replace(/[^\u0000-\u00FF]/g,function($0){return escape($0).replace(/(%u)(\w{4})/gi,"&#x$2;")}); UTF-8转中文 unescape((UTF-8).replace(/&#x/g,'%u').replace(/\\u/g,'%u')....

展开全部概述在2113python代码即.py文件的头部声明即可解析5261py文件中的编码Python 默认脚本文件都是 ANSCII 编码的,当4102文件 中有非 ANSCII 编码范围内的字符的时候就要使用"编码指示"来修正一个 module的定义...
定义一个字符串(原始数据) 将其使用utf8编码成一个数组(编码) 再将其解码成一个字符串(还原)
数据是使用URL引用转义的UTF-8编码字节,因此您需要解码,urllib.parse.unquote()处理从百分比编码数据解码为UTF-8字节,然后透明地处理文本:from urllib.parse import unquoteurl = unquote(url)演示:>...
推荐文章
- 使用Gitlab 搭建私有镜像仓库(外置Nginx)_docker gitlab 使用外部nginx-程序员宅基地
- python之uWSGI和WSGI-程序员宅基地
- Java---简单易懂的KNN算法_jf.knn-%; 9 &-程序员宅基地
- 最新版ffmpeg 提取视频关键帧_从视频中获取flag-程序员宅基地
- 【ARM Cache 系列文章 11 -- ARM Cache 直接映射 详细介绍】
- Objective-C学习计划
- 【数据结构】最小生成树(Prim算法、Kruskal算法)解析+完整代码
- python访问组策略_python 模块 wmi 远程连接 windows 获取配置信息-程序员宅基地
- html把div做成透明背景,DIV半透明层 CSS来实现网页背景半透明-程序员宅基地
- 关机恶搞小程序